End-to-end Data Analytics: Yelp Business Review
Overview
This project deployed a robust, serverless Extract, Load, and Transform (ELT) pipeline on Google Cloud Platform (GCP) to automate the ingestion of Yelp review data. The system ensures data quality through key-based deduplication and specialized category standardization, making the data analysis-ready. The final result supports targeted Machine Learning (ML) analysis and provides real-time Business Intelligence (BI) reporting via Power BI.
Background
- Vast volumes of unstructured customer review text remain dormant, preventing timely business decision-making.
- Businesses struggle to move beyond simple ratings to identify root causes of dissatisfaction (e.g., product vs. service). They lack automated pipelines for proactive customer service and data-driven investment.
This project demonstrates how raw text reviews can be transformed into business-ready insights through automation, analytics, and visualization.
Constraints
- Analysis was limited to a 600k review subset (for ELT) and a 14k subset (for intensive downstream AI) due to cloud cost and resource limitations.
- ELT automation was focused solely on the Reviews data. Business is handled manually, and User data were excluded.
- Visualization was constrained to Power BI due to Looker Studio trial limitations. Automated data refresh for the Power BI has not yet been configured
Key Features
- Event-Driven ELT Pipeline: Automated, serverless pipeline on GCP that transforms raw JSON to a clean, partitioned BigQuery Analytics table.
- Hybrid Downstream Analytics: POC for data enrichment using both VADER sentiment (fast, lexicon-based) and TF-IDF + KMeans (unsupervised themes).
- BI Dashboard Reporting: Developed a Power BI Dashboard with a manual data flow from BigQuery, enabling immediate visualization and access to key customer insights.
Methodology
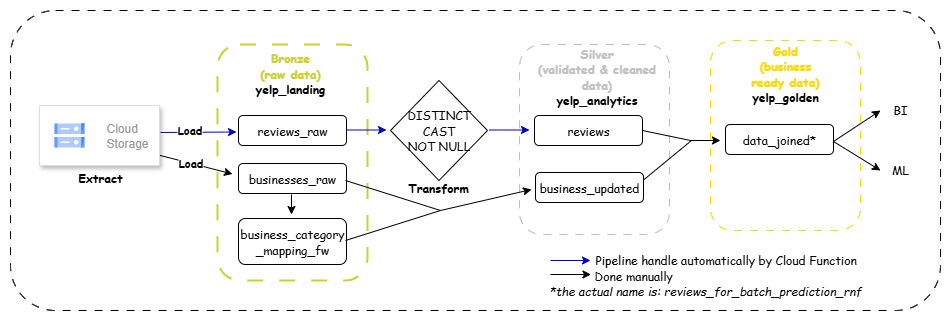
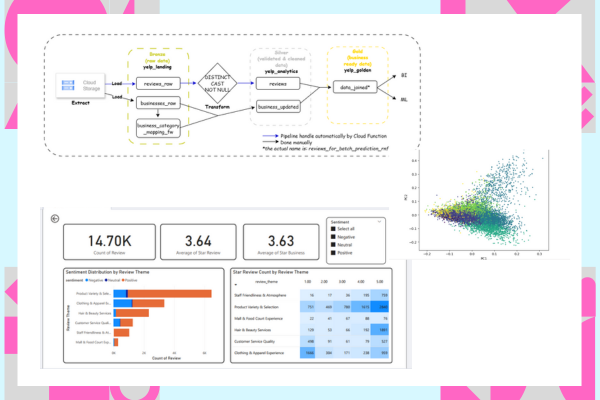
- Landing Zone: The JSON review file will be uploaded to a dedicated Cloud Storage bucket.
- Cloud Function 1: It will handle the initial "Load" part of the ELT pipeline. Specifically, it will get the raw JSON data from GCS into a yelp_landing.reviews_raw table, which will be triggered if a new file is uploaded to the Cloud Storage bucket.
- Cloud Funtion 2: It will handle the "Transform" logic, starting from getting distinct reviews, correcting data types, and removing null reviews, which will be triggered after Cloud Function 1 successfully run. Then, it will save the clean, transformed data to the yelp_analytics.reviews table.
- Downstream Task: After the ELT, the cleansed data is used for downstream task using traditional ML methods (VADER for sentiment analysis, TF-IDF + KMeans for review theme extraction) executed via a Vertex AI Workbench script. This step extracts critical insights for a specific business segment.
- Power BI Dashboarding: A manual data connection is established between the BigQuery table and a Power BI Dashboard. This setup provides stakeholders with immediate visualization of key customer insights, quality metrics, and category performance.
Potential Impact
- Reduced Operational Latency: Automating the entire pipeline with Cloud Functions eliminates manual file processing and scheduling overhead, reducing the time-to-insight from hours to minutes after a new file is uploaded.
- Cost Efficiency in BigQuery: By using a partitioned and clustered analytics table, the project reduces data scanned per query, translating to lower BigQuery compute and storage costs.
- Enhanced Data Quality and Trust: Implementing key-based deduplication in BigQuery guarantees a single source of truth for all review records, eliminating data duplication and improving the reliability of downstream ML models and analytics.
Conclusion
This project successfully established a scalable, serverless data foundation that reduces time-to-insight compared to manual processing. By strategically pivoting to efficient traditional ML methods, I met delivery deadlines while still providing rich analytical output. The system is designed for iterative improvement, positioning it perfectly for future integration of automated reporting and advanced ML workflows.
Categories
Objectives
- Automate Data Ingestion: Develop a cost-efficient, event-driven ELT pipeline using Cloud Functions for immediate review data processing
- Enforce Data Integrity: Standardize 83k+ business categories and implement key-based deduplication in BigQuery to ensure a reliable final analytics table.
- Deliver Actionable Insights: Enable downstream ML analysis and build a Power BI dashboard to visualize customer sentiments and category performance
Tools & Technologies
Data Source
Yelp Open Dataset