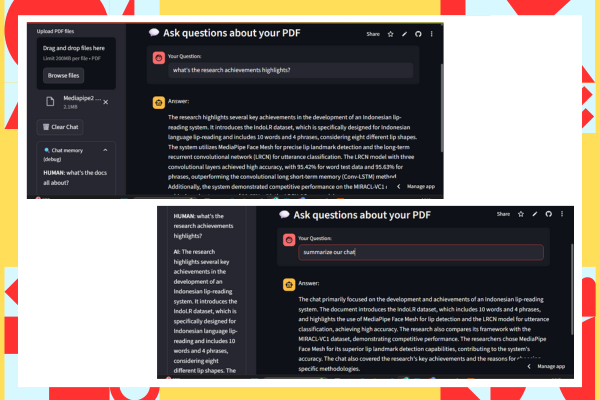
Overview
This project delivers a simple yet powerful web-based chatbot that allows users to interact with their PDF documents using natural language. Leveraging OpenAI's GPT models and Retrieval-Augmented Generation (RAG), the chatbot accurately answers questions by understanding context from user-uploaded PDFs.
Background
Traditional methods of extracting information from PDFs, such as manual copy-pasting, basic PDF conversion tools, or rigid rule-based extraction, can be cumbersome, time-consuming, and prone to errors. This project addresses the need for an intuitive and efficient way to query document content conversationally, enhancing user experience and information retrieval by moving beyond these limitations.
Methodology
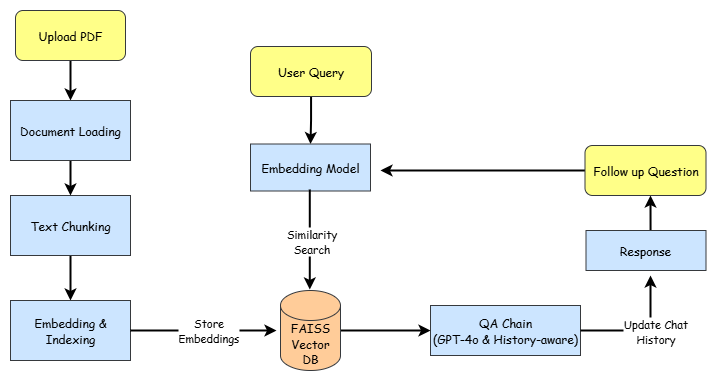
- PDF Processing: PyPDFLoader for uploading and parsing, and RecursiveCharacterTextSplitter for efficient text chunking
- Vector Storage: FAISS for storing and retrieving document embeddings to facilitate fast similarity searches
- Question Answering: LangChain's QA chain combines document knowledge with OpenAI's GPT models for accurate responses
- Conversational Memory: RunnableWithMessageHistory and InMemoryChatMessageHistory maintain per-session chat history for contextually intelligent interactions
- User Interface: Streamlit provides a clean sidebar for PDF uploads and a chat-like interface for seamless user interaction
Conclusion
This project successfully creates an accessible and efficient tool for interacting with PDF documents. By integrating AI capabilities with a user-friendly interface, it significantly streamlines the process of information retrieval from large documents, offering a truly conversational and intelligent experience.
Categories
Objectives
- Enable natural language interaction with PDF documents
- Provide accurate and contextually relevant answers from user-uploaded PDFs
- Enhance information retrieval efficiency through an intuitive web-based chatbot
Tools & Technologies
Data Source
No dataset used